
- skin color: white
- face: invisible
- gender: female
- nudity: semi-nudity
- relationship: unidentifiable

- skin color: black
- face: completely visible
- gender: male
- nudity: semi-nudity
- relationship: unidentifiable
| Zhenyu Wu*1 | Haotao Wang*2 | Zhaowen Wang3 | Hailin Jin3 | Zhangyang Wang2 |
| 1TAMU | 2UT Austin | 3Adobe Research |
* The first two authors contributed equally.
TPAMI 2021 | paper [TPAMI][arXiv] | dataset download [Google Drive][Github] | dataset GUI [Github] | benchmark codes [Github]
We investigate privacy-preserving, video-based action recognition in deep learning, a problem with growing importance in smart camera applications. A novel adversarial training framework is formulated to learn an anonymization transform for input videos such that the trade-off between target utility task performance and the associated privacy budgets is explicitly optimized on the anonymized videos. Notably, the privacy budget, often defined and measured in task-driven contexts, cannot be reliably indicated using any single model performance because strong protection of privacy should sustain against any malicious model that tries to steal private information. To tackle this problem, we propose two new optimization strategies of model restarting and model ensemble to achieve stronger universal privacy protection against any attacker models. Extensive experiments have been carried out and analyzed. On the other hand, given few public datasets available with both utility and privacy labels, the data-driven (supervised) learning cannot exert its full power on this task. We first discuss an innovative heuristic of cross-dataset training and evaluation, enabling the use of multiple single-task datasets (one with target task labels and the other with privacy labels) in our problem. To further address this dataset challenge, we have constructed a new dataset, termed PA-HMDB51, with both target task labels (action) and selected privacy attributes (skin color, face, gender, nudity, and relationship) annotated on a per-frame basis. This first-of-its-kind video dataset and evaluation protocol can greatly facilitate visual privacy research and open up other opportunities.
TL;DR We create the very first dataset, named Privacy Annotated HMDB51 (PA-HMDB51), with both visual privacy attributes and human action labels annotated on human-centered videos, to evaluate privacy protection in visual action recognition algorithms.
We carefully selected five privacy attributes that widely appear in human action videos and are closely relevant to our smart home setting to annotate. The detailed description of each attribute, their possible ground truth values and their corresponding meanings are listed in the following table.
| Attribute | Possible Values & Meaning |
|---|---|
| Skin Color | 0: Skin color of the person(s) is/are unidentifiable. |
| 1: Skin color of the person(s) is/are white. | |
| 2: Skin color of the person(s) is/are brown/yellow. | |
| 3: Skin color of the person(s) is/are black. | |
| 4: Persons with different skin colors are coexisting.* | |
| Face | 0: Invisible (< 10% area is visible). |
| 1: Partially visible (≥ 10% but ≤ 70% area is visible). | |
| 2: Completely visible (> 70% area is visible). | |
| Gender | 0: The gender(s) of the person(s) is/are unidentifiable. |
| 1: The person(s) is/are male. | |
| 2: The person(s) is/are female. | |
| 3: Persons with different genders are coexisting. | |
| Nudity | 0: No-nudity w/ long sleeves and pants. |
| 1: Partial-nudity w/ short sleeves, skirts, or shorts. | |
| 2: Semi-nudity w/ half-naked body. | |
| Relationship | 0: Relationship is unidentifiable. |
| 1: Relationship is identifiable. |
* For "skin color" and "gender", we allow multiple labels to coexist. For example, if a frame showed a black person’s shaking hands with a white person, we would label "black" and "white" for the "skin color" attribute.
Example annotated frames are shown in the following table.
| Frame | Action | Privacy Attributes |
|---|---|---|
|
brush hair |
|
|
situp |
|
Label distribution per privacy attribute in our dataset are shown in the following figure. The rounded ratio numbers are shown as white text (in % scale).
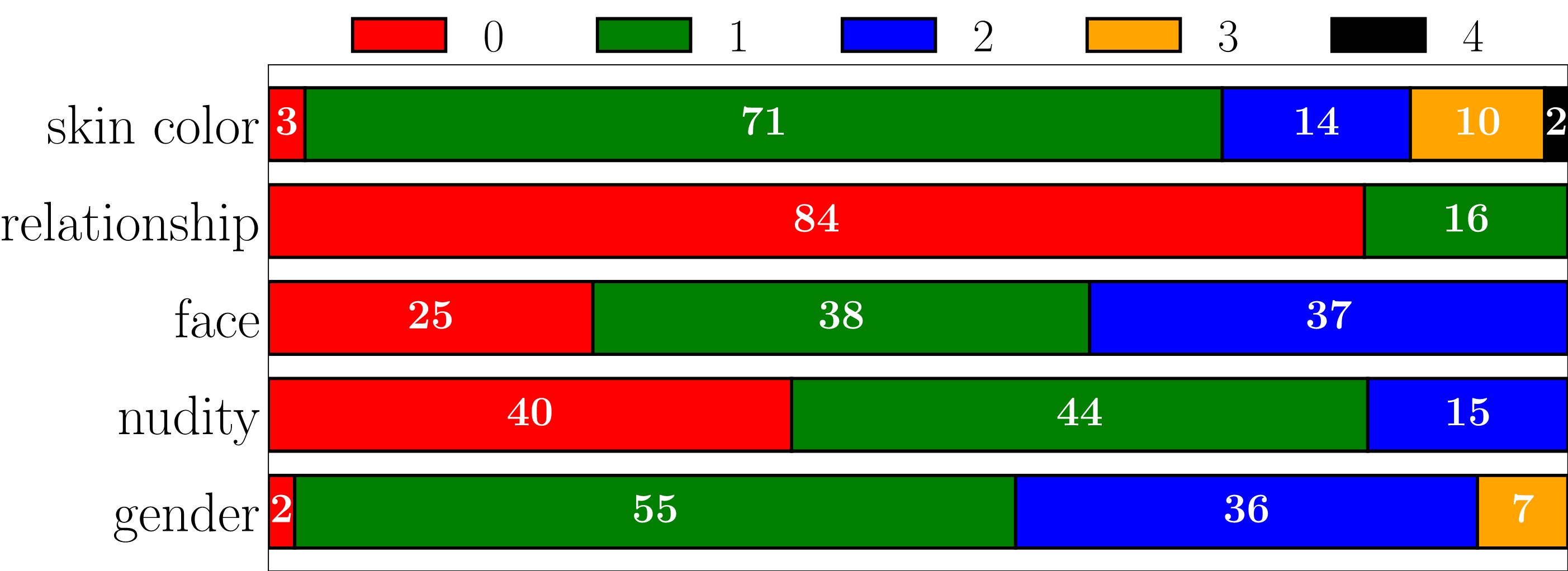
We also provide a GUI to view frame-wise privacy attribute annotations in our dataset. Please refer to its README file for more instructions on using the GUI.
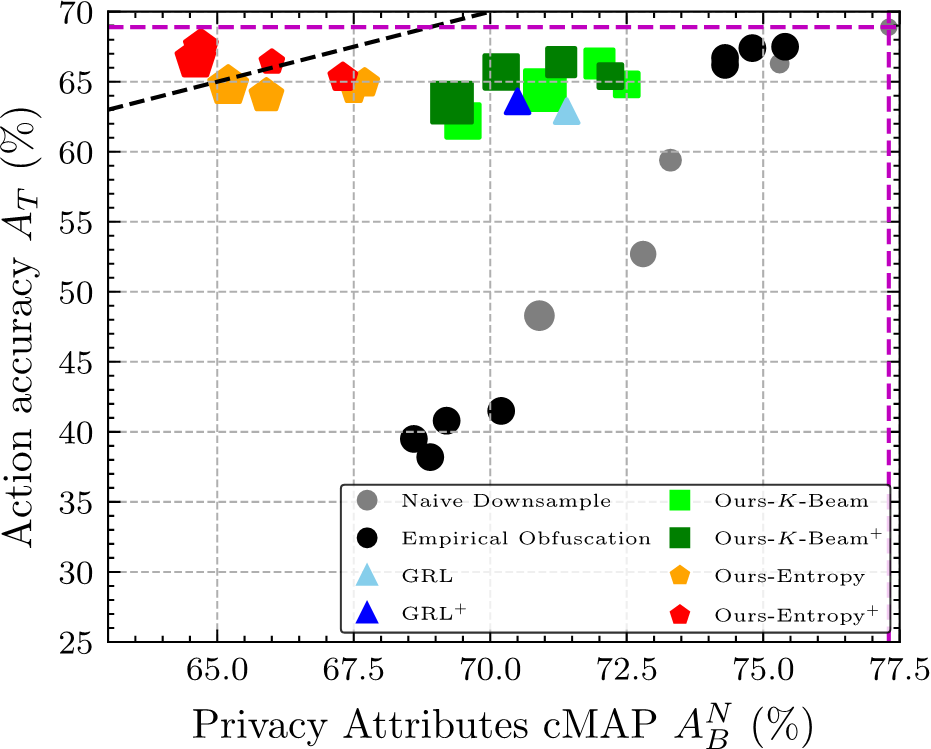
We designed and benchmarked multiple visual privacy preserving machine learning algorithms on our dataset. Results are shown in the following figure, where smaller \(A^N_B\) represents better privacy protection, and larger \(A^T\) represents better action recognition accuracy. Vertical and horizontal purple dashed lines indicate \(A^N_B\) and \(A^T\) on the original non-anonymized videos, respectively. The black dashed line indicates where \(A^N_B\) = \(A^T\). Privacy-utility trade-off of different methods are shown in different colors.
For more details, please check our paper. If you use our dataset, please cite the following BibTeX.
Z. Wu, H. Wang, and Z. Wang were partially supported by NSF Award RI-1755701. The authors would like to sincerely thank Scott Hoang, James Ault, and Prateek Shroff for assisting the labeling of the PA-HMDB51 dataset, and Scott Hoang for his contribution in building the GUI.